🏆 Future Research Award
2025 K-Data Science Conference (Research & Poster Presentation)
📌 Problem Statement
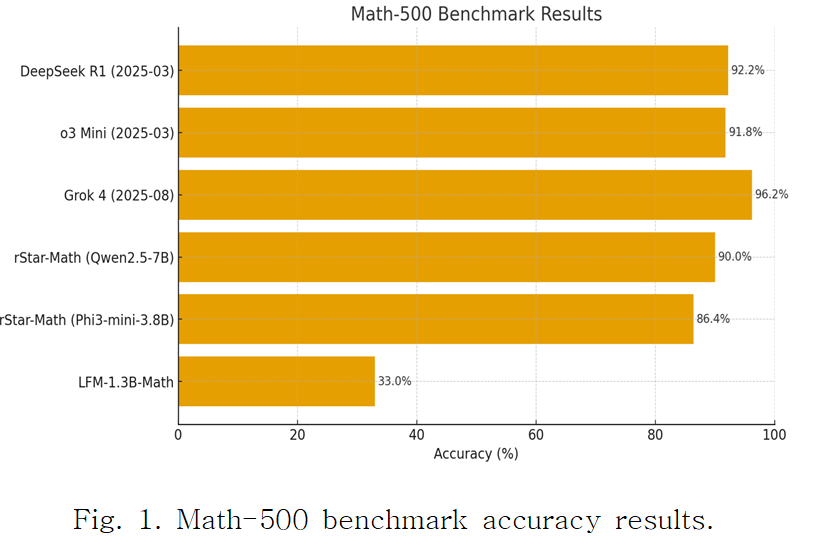
High Math-500 accuracy is primarily achieved by large-scale LLMs, while compact models remain underrepresented, with LFM showing limited performance.
Recent advances in large language models (LLMs) have demonstrated strong performance in general language understanding; however, mathematical reasoning remains a challenging domain, particularly under resource-constrained settings.
Most existing approaches rely on large-scale models or supervised fine-tuning (SFT), which limits practical deployment and increases data dependency.
This project addresses the following research question:
Can mathematical reasoning ability be significantly improved using reinforcement learning alone, without supervised fine-tuning, on a compact language model?
💡 Proposed Solution
(1) Curriculum Learning
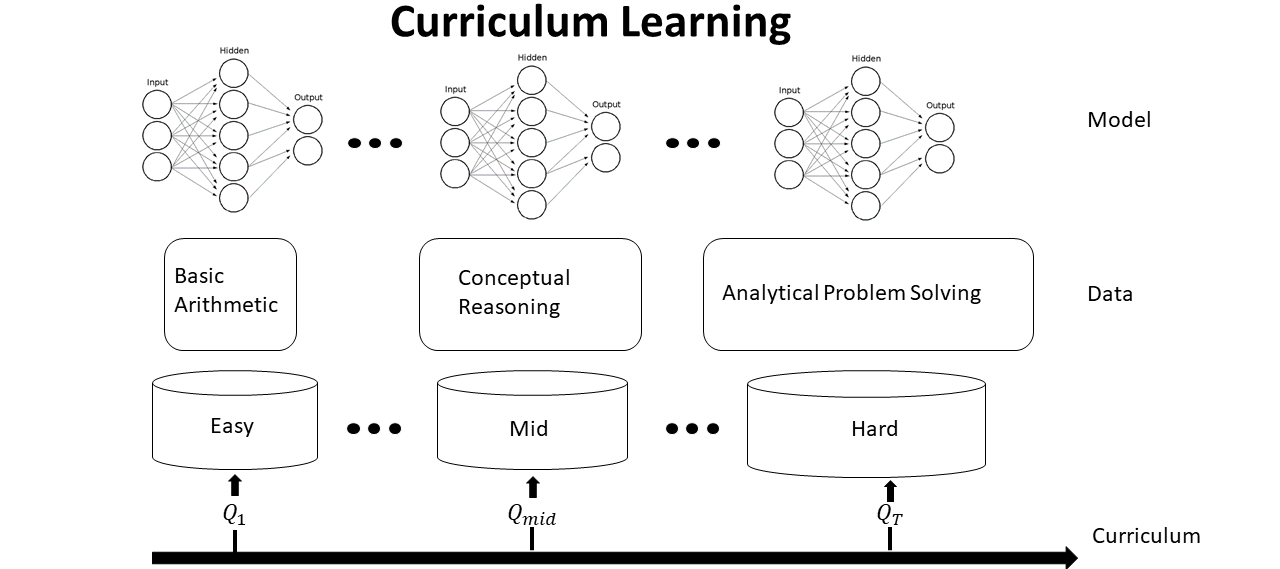
The training process progresses from easy to hard problems, enabling stable reasoning acquisition and preventing early-stage failure.
(2) KL-free Policy Optimization (ZeroGRPO)
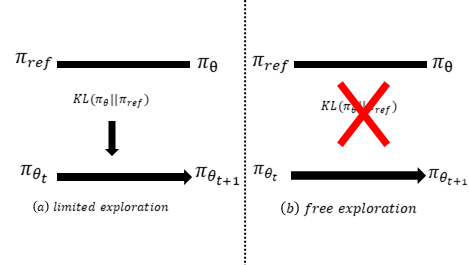
Removing the KL-divergence constraint allows compact models to freely explore diverse reasoning trajectories.
(3) Simple Reward Design with Reasoning-Length Penalty
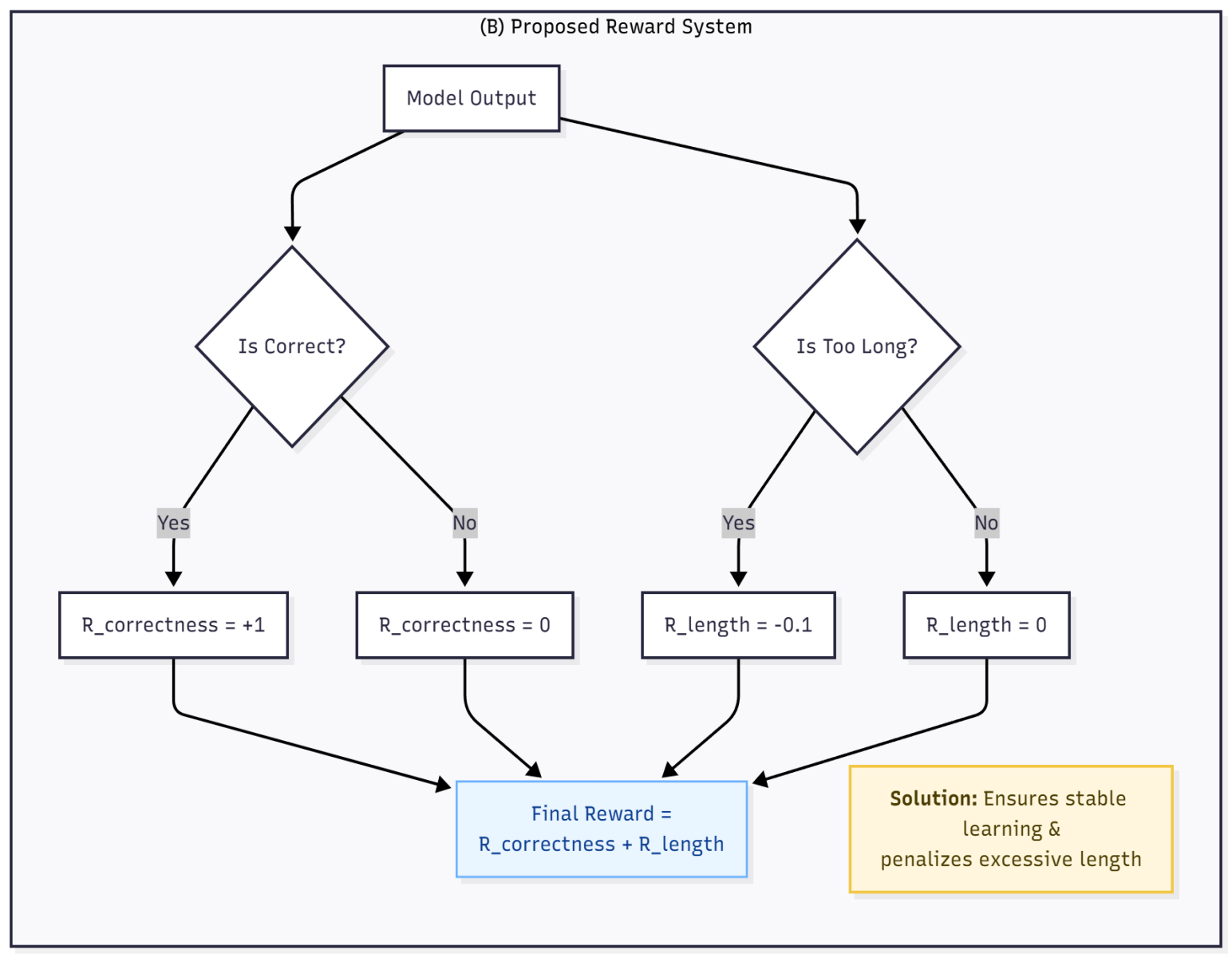
A minimal reward based on answer correctness and format validity, combined with a mild penalty on excessively long reasoning.
Together, these three components form a unified reinforcement-learning framework that enables effective mathematical reasoning in compact language models without increasing model size or supervision cost.
🛠️ Technical Overview
- Base Model:
- DeepSeek-R1-Distill-Qwen-1.5B (text-only lightweight LLM)
- Training Method:
- Reinforcement learning using a modified GRPO framework
- Removal of KL-divergence regularization to allow unconstrained policy exploration
- Key Techniques:
- Zero-KL policy optimization (ZeroGRPO)
- Simple and stable reward design based on answer correctness and format consistency
- Curriculum learning strategy with progressively increasing difficulty
- Evaluation Benchmark:
- Math-500 benchmark covering multiple mathematical domains and difficulty levels
🎬 Results and Achievements
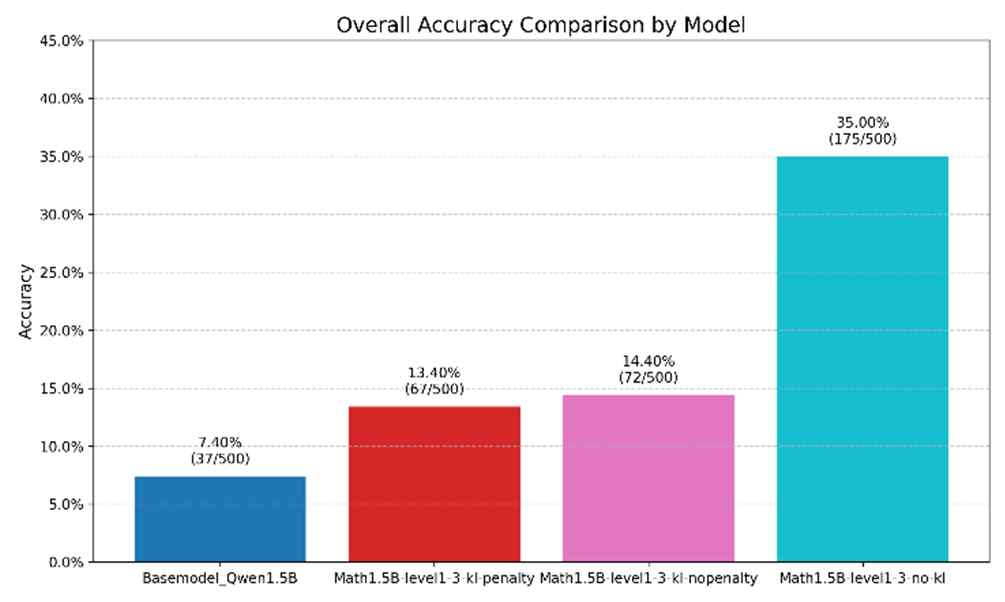
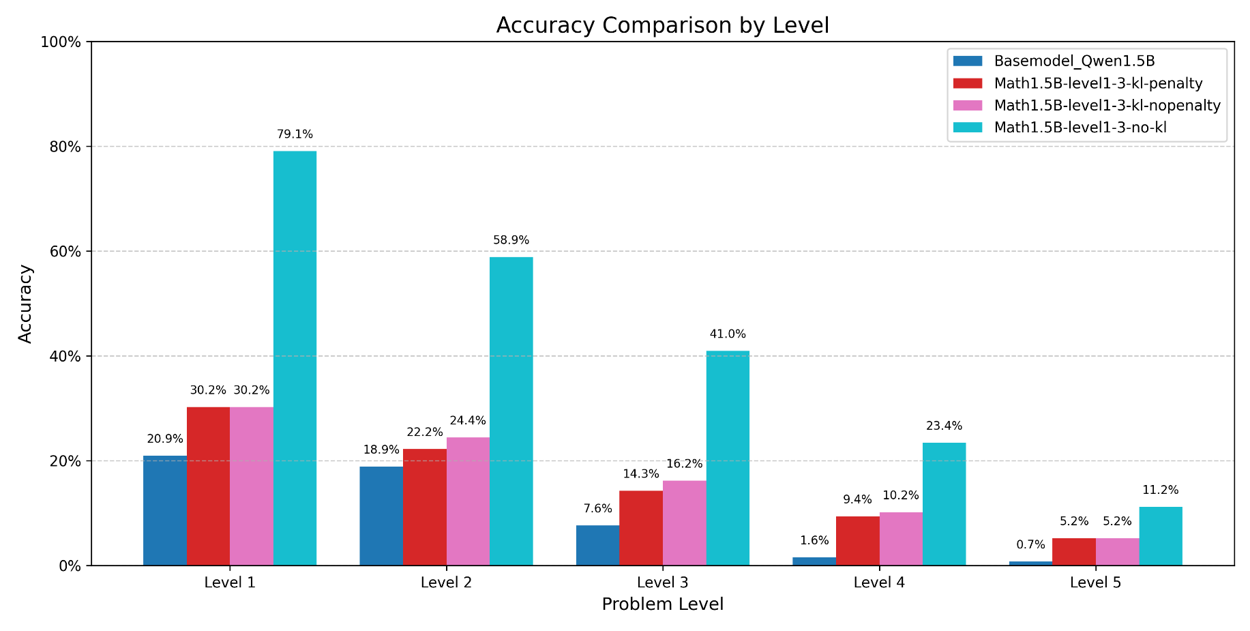
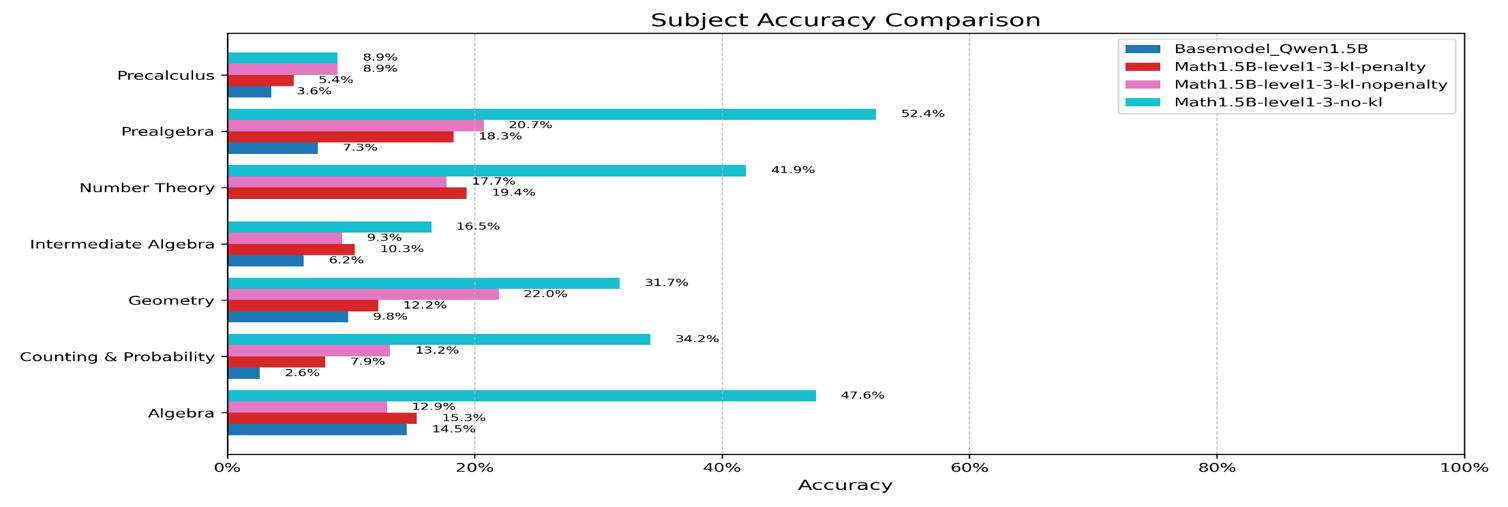
- Substantial Performance Improvement:
- Achieved up to 3.7× accuracy improvement over the base model on Math-500
- Outperformed standard GRPO and penalty-based variants under identical settings
- Efficiency and Practicality:
- Demonstrated that strong mathematical reasoning can be achieved with a 1.5B-parameter model
- No supervised fine-tuning required, reducing data and annotation costs
- Research Contribution:
- Validated that removing KL constraints is particularly beneficial for small models
- Showed the effectiveness of curriculum learning in stabilizing RL-based reasoning training
- Outcome:
- Research results accepted for poster presentation at the 2025 K-Data Science Conference
- Selected as a funded research project by the conference committee
📄 Related Publication
SuperSmall-R1: A Lightweight Reinforcement Learning Model for Mathematical Reasoning
Jaegun Lee, Janghoon Choi
Journal of The Korea Society of Computer and Information (KCI-indexed), 2025
- Introduces a reinforcement-learning-only training strategy for compact reasoning models
- Proposes ZeroGRPO by removing KL-divergence constraints
- Demonstrates significant performance gains on Math-500 under strict resource constraints
Commemorative Photo


