👉 Paper
👉 Project Page
Abstract
This project presents an end-to-end framework for automatically understanding video content and generating aligned multimedia outputs. The proposed system analyzes visual semantics from input videos and produces structured representations that enable downstream generation and evaluation. Our approach demonstrates robust performance across diverse video scenarios, highlighting its applicability to real-world multimedia pipelines.
Introduction
With the rapid growth of multimedia content, automated understanding and generation of video-related information have become increasingly important. Recent advances in vision-language models have enabled more accurate semantic interpretation of visual data. In this project, we focus on designing a unified pipeline that connects video understanding with generation-oriented objectives, emphasizing scalability and qualitative consistency.
Method
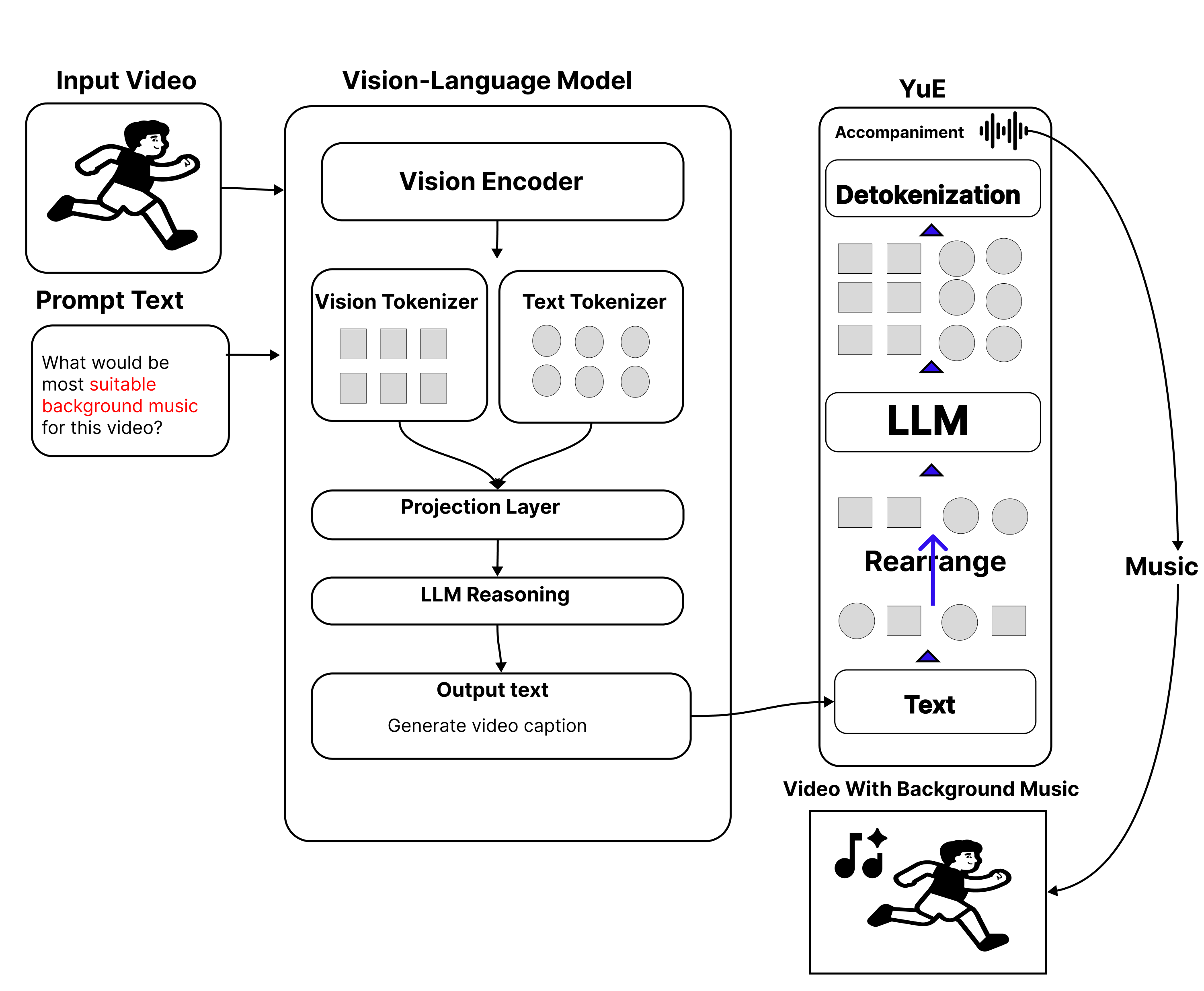
Our method consists of a structured pipeline that processes input videos and transforms them into semantically meaningful representations. The overall architecture is designed to be modular, allowing each component to be independently improved or replaced.
Figure. Overall architecture of the proposed framework.
Result
We evaluate our approach through qualitative results that demonstrate the effectiveness of the proposed framework. The following examples illustrate representative outputs under different conditions.